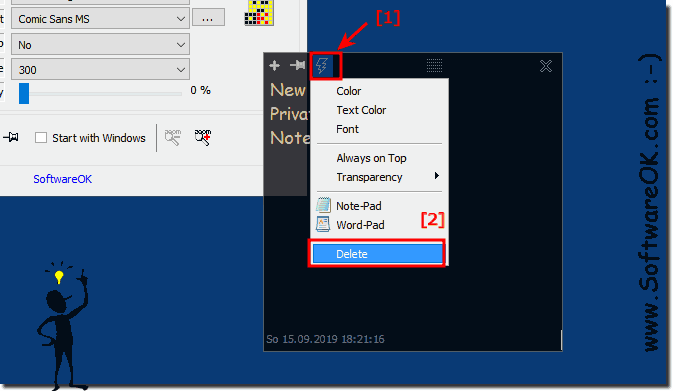
You can delete the content of the note beforehand and then Close, this will cause the same notes without content to be closed, are also deleted when closing, the content also does not end up on a server abroad and is also not used for program optimization to make the program better and they are not read like for Amazon by the favorable Indian employee to improve customer satisfaction.
You can easily use this easy and fast note-erase solution on older versions of Microsoft's Windows operating systems, whether it's a Windows desktop, tablet, Surface Pro / Go, or even a server operating system.
Many users of Windows 11, 10, 8.1 use the small digital notes, as sticky notes on the desktop, are more environmentally friendly than who uses paper The
Data protection has always been important to me, I do not want to allow notes to be synchronized between PCs, even if I am logged in with the same Microsoft account, am I ensuring that the sticky notes are not saved on another PC?
Notes, I do not want to save anywhere else, I want to make sure that my notes are actually deleted in Windows 10, that you can not find them, never make a backup, where they can then be restored by everyone, the location of the Sheet music is important to me, for example not that the notes are copied from a PC with Windows 10 to a PC with Windows 10 HOME?
Is it safe that no one can restore my private notes as with Sticky Notes in Windows, making it impossible to restore notes on Windows 10 is important to me, data protection and privacy, so the Windows Notes should not have a backup of my notes and even at all never move to another PC, I don't want that, is that possible?
This website does not store personal data. However, third-party providers are used to display ads, which are managed by Google and comply with the IAB Transparency and Consent Framework (IAB-TCF). The CMP ID is 300 and can be individually customized at the bottom of the page. more Infos & Privacy Policy ....